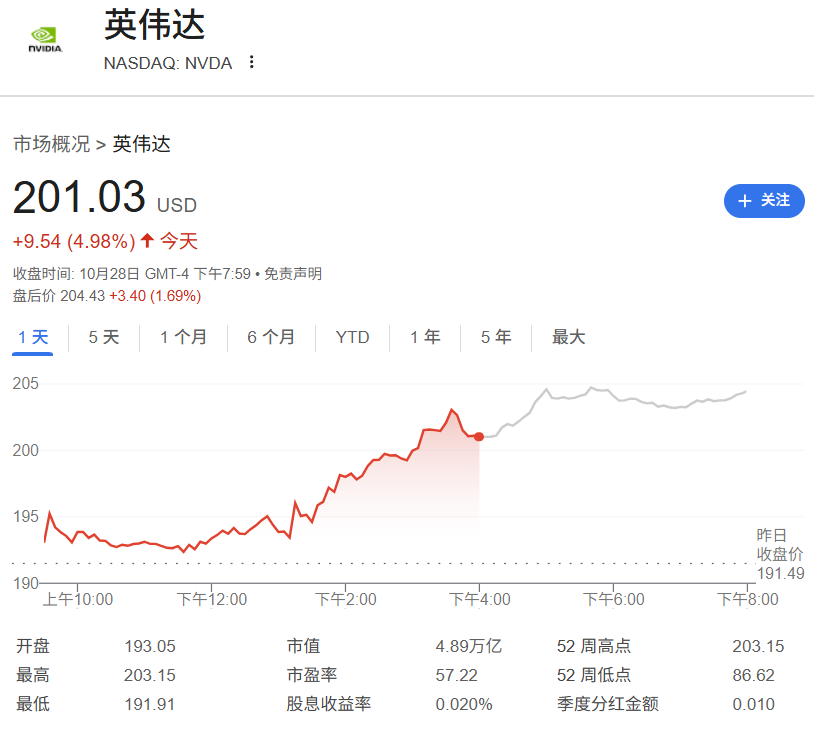
前言
每次听到“智能体(Agent)”,你是不是会想到一个能替你完成复杂工作、还能自己查资料、用工具、写代码的“数字同事”?2024年我们看到的更多是“工作流+LLM”的辅助形态,能帮你加速,但仍需要人盯着。而到了2025年,几个关键“拼图”同时到位:更强的推理模型(OpenAI o3-mini、GPT-5;Anthropic Claude 4)、更完善的工具协议(MCP)、更可靠的编排与状态管理(LangGraph)、更长的上下文与结构化输出,再加上“深度研究”类Agent开始实用。结果是——Agent开始能独立做事、能持续思考、能并行调用工具、能完成更长链路任务。
读完本文,你能清楚地解释这两年的差异、选型正确的框架与API,并能搭一套可验证的Agent原型!
核心技术概念解析
什么是Agent(通俗解释)
- 智能体(Agent)——像一个能看懂指令、会自己拆分任务、能调用外部工具、还能在电脑里“点点点”完成实际操作的数字助理。
- 术语解释:
- 推理模型(Reasoning model)——会“多想一步”的模型(如o3-mini、Claude 4),适合复杂多步任务。
- 结构化输出(Structured Outputs)——模型按预定义Schema输出,便于机器消费与工具衔接(OpenAI o3-mini支持)。
- 工具并行/扩展思考(Extended thinking with tool use, parallel tools)——模型在推理过程中交错或并行使用外部工具,提升复杂任务完成率(Anthropic Claude 4)。
- MCP(Model Context Protocol)——标准化让模型安全访问数据源与工具的开放协议(Anthropic牵头)。
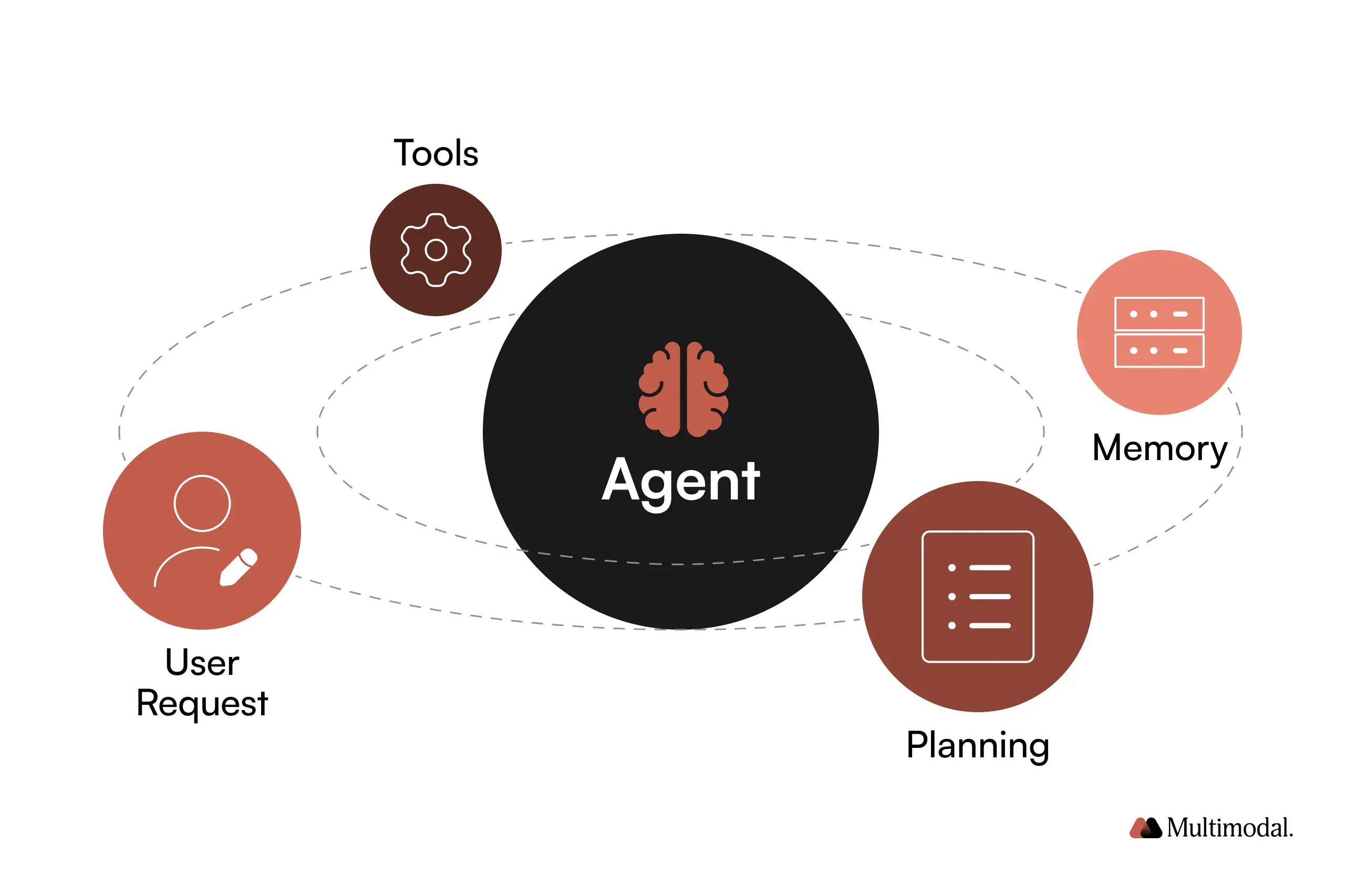
2024年的Agent:基线能力与生态拼图
- 评测与环境起步:
- AgentBench(ICLR’24)提出面向多环境的Agent评测框架(论文与GitHub,2023–2024)。来源:AgentBench论文与仓库(ResearchGate;GitHub)。
- OSWorld(NeurIPS 2024):在真实电脑环境中评测多模态与电脑使用能力,提供VM/Docker环境与任务集。来源:OSWorld GitHub(2024-04-11; 2024-10-22更新)。
- 框架与编排:
- LangGraph引入循环与状态持久化,强调“非DAG”以支持Agent式反复决策、工具执行与人类介入。来源:LangGraph README(2024)。
- 接口与多模态:
- OpenAI Realtime API(2024-10)为实时语音/音频等多模态交互打基础。来源:OpenAI Realtime API(2024-10-01)。
- 标准化趋势起步:
- MCP在2024年11月开源并形成SDK(Python/TS),为2025年工具与数据集成提供通用“USB-C”式接口。来源:MCP python-sdk(官方GitHub)。
生活化类比:2024年的Agent像“宏+脚本+LLM”的组合,你需要搭工作流、连接工具、设计评测,Agent能做事但不够“独立”。
2025年的Agent:能力跃迁与工程就绪
- 推理模型显著提升:
- OpenAI o3-mini(2025-01-31):支持函数调用与结构化输出,针对STEM优化;在SWE-bench Verified上达到48.9%(o3-mini-high)。来源:OpenAI o3-mini发布页。
- GPT-4.1(2025-04-14):SWE-bench Verified 54.6%;支持1百万token上下文,显著提升长上下文理解与指令跟随,明确用于“更可靠的Agents”。来源:GPT-4.1发布页。
- Anthropic Claude 4(2025-05-22):引入“Extended thinking with tool use(beta)”“并行工具”“内存能力”,SWE-bench Verified:Opus 4 72.5%、Sonnet 4 72.7%,API侧提供MCP connector、Files API与code execution tool。来源:Anthropic Introducing Claude 4。
- Agent产品形态:
- ChatGPT“deep research”Agent(2025-02-02):能独立进行多步网络研究,面向复杂信息综合。来源:OpenAI deep research发布。
- 协议与生态:
- MCP在2025年进入开发者生态与桌面集成(Claude Desktop),用于安全接入数据源与工具。来源:MCP python-sdk README。
- 编排与状态:
- LangGraph与相关生态继续用于构建具循环/状态的多Actor应用,支持人类介入、长任务暂停恢复等工程需求。来源:LangGraph README。
- 趋势与电脑使用:
- Google在2024-12公开“agentic时代”并在2025持续强化企业用例(Google Blog),电脑使用与界面控制是重要方向。来源:Google Blog(2024-12-19;2025 Keyword)。

流程图:2025 Agent标准架构 目标 → 任务分解(推理模型, 长上下文) → 工具策略(并行/交错调用;结构化输出) → 执行(MCP连接工具/数据;电脑使用环境如OSWorld场景) → 记忆与状态(LangGraph状态持久化;Files API;内存文件) → 监控与安全(系统卡/红队评估;审计) → 人工介入(关键节点Pause/Review) → 收敛与交付(报告/补丁/数据操作)
数据点与事实(可验证):
- SWE-bench Verified:OpenAI GPT-4.1(54.6%);OpenAI o3-mini-high(48.9%);Anthropic Claude 4 Sonnet与Opus(72%+)。来源:OpenAI与Anthropic发布页。
- 长上下文:GPT-4.1支持1M token,适配大代码库与长文档。来源:OpenAI GPT-4.1。
- 工具并行与扩展思考:Anthropic在Claude 4中公开beta与并行工具能力。来源:Anthropic。
- 结构化输出与函数调用:OpenAI o3-mini支持Structured Outputs与function calling。来源:OpenAI o3-mini。
- 协议与集成:MCP官方SDK与规范,用于资源/工具/提示暴露与多传输(stdio/SSE/HTTP)。来源:MCP python-sdk。
对比与价值分析
对比表:2024 vs 2025 Agent(核心维度)
| 维度 | 2024 Agent | 2025 Agent | 证据与来源 |
|---|---|---|---|
| 推理能力 | 以通用LLM为主,规划与长链条任务易退化为工作流 | 推理模型跃迁(o3-mini、GPT-4.1、Claude 4),复杂任务成功率显著提升 | OpenAI o3-mini、GPT-4.1;Anthropic Claude 4 |
| 评测基线 | AgentBench、OSWorld等基准起步 | SWE-bench Verified显著跃升;企业代码场景更可用 | OpenAI GPT-4.1、o3-mini;Anthropic Claude 4 |
| 工具调用 | 以函数调用与工作流编排为主 | 并行工具调用与扩展思考(交错推理+工具);结构化输出成标配 | Anthropic Claude 4;OpenAI o3-mini |
| 上下文 | 128k上下文较常见 | 1M上下文(GPT-4.1),长文档与大代码库成为常态 | OpenAI GPT-4.1 |
| 协议与生态 | MCP发布(2024-11),生态初成 | MCP在API与桌面集成(MCP connector、Claude Desktop),规范化数据与工具访问 | MCP python-sdk;Anthropic Claude 4 |
| 编排与状态 | LangGraph提供循环与状态持久化;多Agent初步 | LangGraph等成熟应用于长任务、暂停/恢复、人类审查;工程可靠性提升 | LangGraph README |
| 产品化 | 多为Copilot/Workflow辅助 | 深度研究类Agent落地(独立多步网上研究);企业API增强(Files、Code Execution) | OpenAI deep research;Anthropic Claude 4 |
| 安全与治理 | 红队与系统卡开始进入 | 系统卡更全面;并行工具与扩展思考下降低“捷径/漏洞”行为 | OpenAI o3-mini系统卡;Anthropic安全说明 |
| 电脑使用 | OSWorld基线,能力差异大 | “Agentic时代”趋势明确;电脑使用与界面控制场景持续强化 | OSWorld;Google Blog趋势 |
局限性与边界(务必了解)
- 评测的可比性:SWE-bench成绩高度依赖评测脚手架与工具设置(OpenAI与Anthropic均给出方法说明);比较时需同等条件。来源:两家发布文内方法节。
- “电脑使用”媒体报道的高分需谨慎:未获得论文原文链接的具体数值不作为结论;以OSWorld基准与官方趋势为主。
- 并行工具与扩展思考带来的新风险:工具安全、越权操作与“捷径”倾向需要更严格的审计与策略约束(Anthropic强调降低“shortcut behavior”)。
案例研究(简化示例):用LangGraph + MCP搭一个“研究与修补”双栈Agent
场景:你要做两件事——1)深度网上研究并输出结构化报告;2)在仓库里修一个已知Bug并通过测试。
- 解决方案对比:
- 2024做法:基于工作流(DAG)+LLM调用工具,容易在长链条任务上退化,需要多人工干预。
- 2025做法:使用推理模型(如GPT-4.1)、结构化输出Schema、LangGraph循环/状态、MCP连接数据与工具;可在同一Agent中交错“研究”与“修补”。
- 伪代码要点(示意,非可运行):
- LangGraph中定义两个节点:research_agent(调用浏览器/检索工具,输出报告JSON Schema)与 fix_agent(调用代码编辑与测试工具,输出diff与测试结果)。
- 条件边:若research未完成→继续;若fix失败→回溯到research收集更多线索;MCP暴露资源(知识库文档、配置)与工具(执行测试、生成diff)。
- 结构化输出:研究报告以JSON Schema输出;代码变更以统一diff格式输出;保证下游工具可消费。
这类设计更契合2025的能力:推理更强、工具更规范、输出可机读、状态可持久;失败可回溯,人类可介入关键节点审查。
进阶内容:工程技巧与趋势
- 高可靠性技巧
- 结构化输出优先(OpenAI o3-mini支持),统一Schema减少失败率。
- 并行工具谨慎使用:限制并行度与工具权限,审计日志全量保留(Anthropic建议与API能力)。
- 长上下文合理切片:GPT-4.1虽支持1M,但要做“needle-in-haystack”定位与分块检索,避免上下文稀释。
- 未来3年趋势(预测)
- Reasoning + Tools 一体化成为默认路径;“扩展思考+并行工具”常态化。
- 协议与生态标准(MCP)在更多平台落地,连接更多企业数据与内网工具。
- 电脑使用与界面控制走向更稳健评测(OSWorld演进),自动化办公与测试成为高频场景。
来个总结
- 核心观点
- 2025的Agent不再只是“工作流+LLM”的组合,更像“可独立工作”的智能体:会规划、会并行用工具、能长时间持续思考。
- 推理模型与工程配套同时升级(o3-mini、GPT-4.1、Claude 4 + MCP + LangGraph),带来显著的真实任务成功率提升(SWE-bench Verified为证)。
- 协议化(MCP)、结构化输出、长上下文是工程就绪的三大支柱;电脑使用场景需要以OSWorld等基准与官方材料为主,谨慎对待未经论文佐证的媒体成绩。
- 行动建议
- 给你的Agent定义一个结构化输出Schema,并改造工具链以Schema为中心。
- 在LangGraph中加入“人工审查节点”,为删改、发布等高风险操作提供“人管控”。
- 使用MCP将企业数据与工具接入,统一鉴权与日志;从一个小场景(如自动化测试修补)做起。
你会从哪个场景开始把Agent“拉长链条”?是“深度研究+决策”还是“测试修补+发布”?思考一下!
© 版权声明
文章版权归作者所有,未经允许请勿转载。